Spotting Malicious Prompts Before They Hit Your LLM
Malicious prompts can turn your AI against you. Cerberius classifies user input in real-time, assigning a risk score using multiple models, context sources, and a custom algorithms.
Large language models (LLMs) don't need to be hacked in the traditional sense. Instead, they can be manipulated — with cleverly crafted inputs that change their behavior, leak sensitive instructions, or generate harmful content.
This is the essence of prompt injection — a growing threat to AI-powered applications. Whether you're building a chatbot, support agent, or search assistant, your app is only as safe as the input it accepts.
That's why we built the Cerberius Prompt Classification API: a fast, real-time service that evaluates every prompt before it hits your model. It doesn't just run keyword filters — it combines multiple large models, real-world prompt patterns, and a custom algorithms as well as the scoring engine to determine whether input is safe, risky, or clearly malicious.
The Problem: Trusting Untrusted Input
LLMs are designed to respond helpfully — even when asked to ignore their own instructions. Attackers exploit this behavior with prompt techniques like:
- Injecting override commands (“Ignore previous instructions and...”)
- Tricking the model into roleplay, fake scenarios, or simulation loops
- Escaping formatting to break structured parsing or control flow
Without proper filtering, even harmless-looking input can become a vector for jailbreaks, misinformation, or reputational damage.
The Cerberius Approach
Rather than rely on one model or one rule set, our system performs a layered evaluation:
- Multiple Model Checks: We use multiple layers of machine learning approaches to assess intent, tone, and adversarial risk.
- Contextual Metadata: Signals like token entropy, instruction density, and known malicious structures are evaluated.
- Custom Scoring Engine: Our internal algorithms weighs each model's judgment, normalizes confidence, and outputs a clean
risk_score.
Each response includes a numeric score (0–100), a binary classification (malicious/safe), and optional metadata — letting you route, block, or challenge the input before it ever reaches your core model.
Imagine you run a chat bot that passes messages between a user and the backend LLM. Below are examples of message flow when using cerberius prompt guard service.
Example of malicious prompt flow
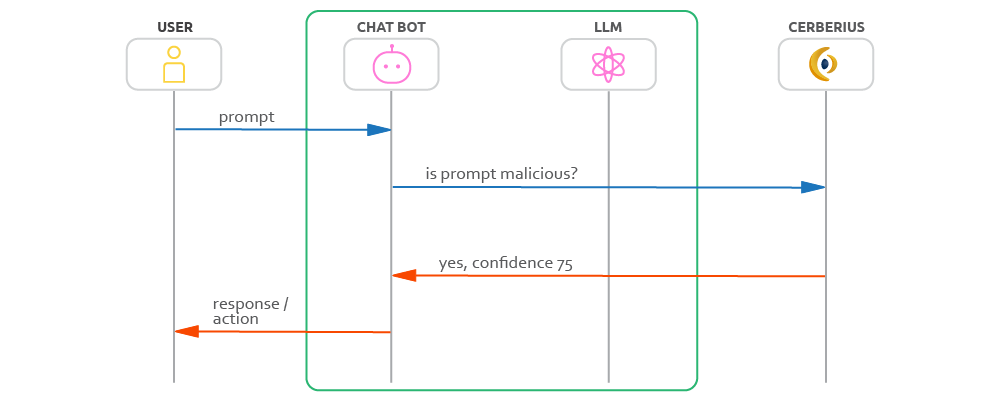
This ensures that harmful prompts are blocked at the gateway, keeping your LLM safe and uncompromised.
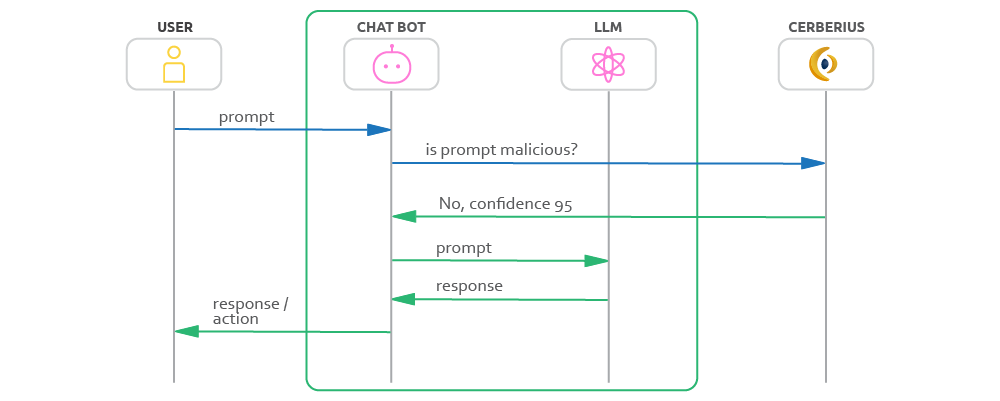
Below is the message flow for a safe, non-malicious prompt, which proceeds through to your LLM as expected.
Example of non-malicious prompt flow
Use Cases: Filtering at the Front Line
The Prompt Classification API helps teams secure and control LLM usage across a wide range of environments:
- Chatbots: Prevent jailbreak attempts, prompt manipulation, and offensive content in real-time.
- Search Interfaces: Detect prompts designed to extract internal logic, hidden instructions, or exploit unintended behavior.
- Content Moderation: Flag potentially harmful or policy-violating prompts before they generate output.
- LLM Gateways: Add a security layer in front of commercial APIs like OpenAI, Claude, or Cohere — ideal for rate-limiting and filtering at scale.
- Internal Tools: Protect smaller, self-hosted models like Mistral, Gemma, or Phi-3 used in customer support, document analysis, or internal copilots.
- Developer Sandboxes: Monitor prompt activity in experimental or low-code environments where users interact freely with models.
- Enterprise Compliance: Enforce prompt-level policies before text is processed or logged — helping with data protection and regulatory requirements.
Defense in Depth, By Design
There's no single model that can catch all prompt attacks. That's why Cerberius was designed to layer multiple perspectives, normalize their confidence, and give you a stable, real-world answer — fast enough to use in production.
It's not just about blocking the worst. It's about knowing what's risky, tracking evolving attack patterns, and giving your application the tools to adapt.